Herbgrind Part 7: What About Square Root?
Welcome back to my series of posts on Herbgrind, a dynamic analysis tool that finds floating point issues in compiled programs. The purpose of this series is to explain how Herbgrind works and the principles behind its design. To do that, we started with a simple hypothetical computer called the “Float Machine”, which is just enough to capture the interesting floating point behavior of a real computer, like the one that’s probably sitting on your desk. Now, we’re bringing Herbgrind’s analysis to the real world, making it computable and fast.
![]()
If you missed the previous posts in this series, you might find this one a bit confusing, so I suggest you go back and read it from the beginning. If that’s too much reading, the first implementation post has a short summary of the lead up, and introduces the Valgrind framework which this post builds on. In this post, I’m going to assume you know what I mean when I talk about “the Real Machine”, or “thread state”.
In the last post we talked about how to emulate the Real Machine on a real-world computer. We used MPFR to simulate the program much more accurately than normal floats can, and used carefully stored shadow values to keep persistent, high-precision values between different operations. Then, we could compute a “correct” answer for a particular run of the program, and compare it to what was computed.
Doing this is pretty simple in general, but not always. On the VEX level, implementing “Real” operations amounts to looking at each instruction when instrumenting, and adding extra code if it’s a math operation of some sort, like an addition, or a subtraction. This works great for simple operations, but not all math operations on a computer can be done in a single instruction. While operations like addition and multiplication tend to have built-in instructions, there are other functions like “square root” that don’t1.
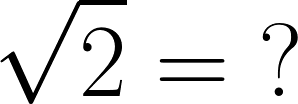
Shadowing Transcendental Functions
Functions, like square root, that can’t be defined directly as a
(finite) series of arithmetic operations are called “transcendental
functions”, because they “transcend” the simple operations. This makes
them pretty hard to compute, but luckily some really smart people
figured it out a long time ago. Those people wrote libraries, like GNU
libm which use mathematical bit-twiddling to compute these functions
accurately for the standard hardware float sizes, and MPFR includes
most of them in high-precision.
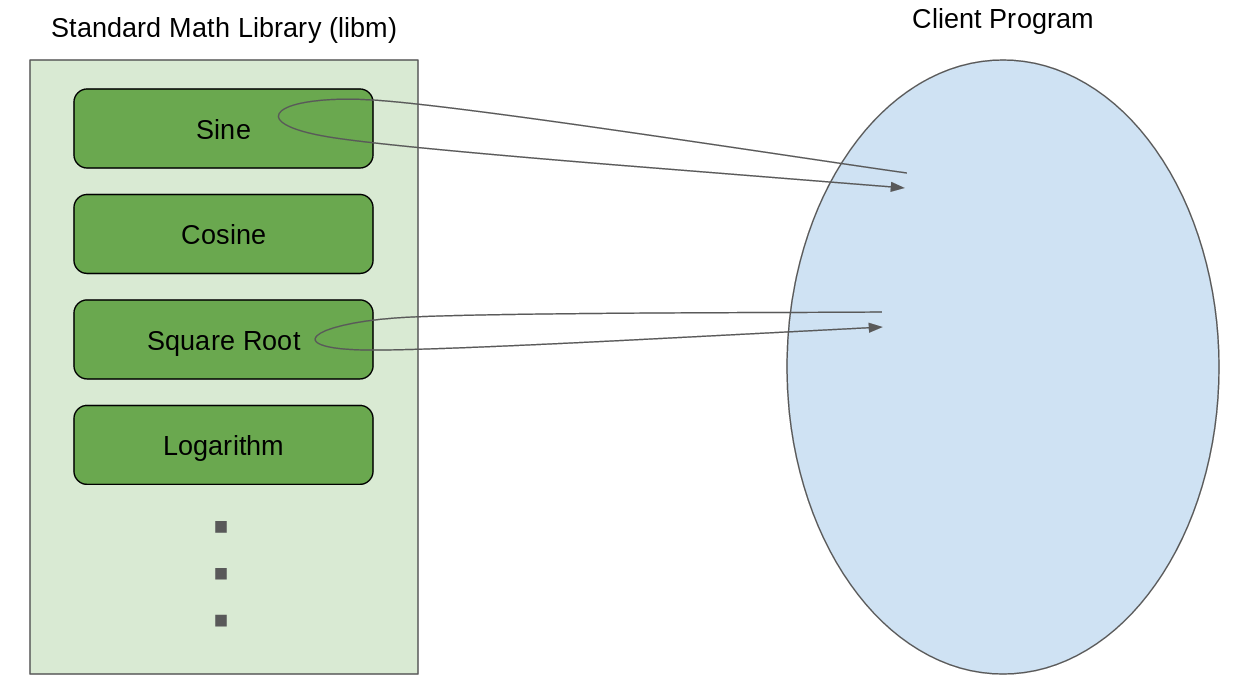
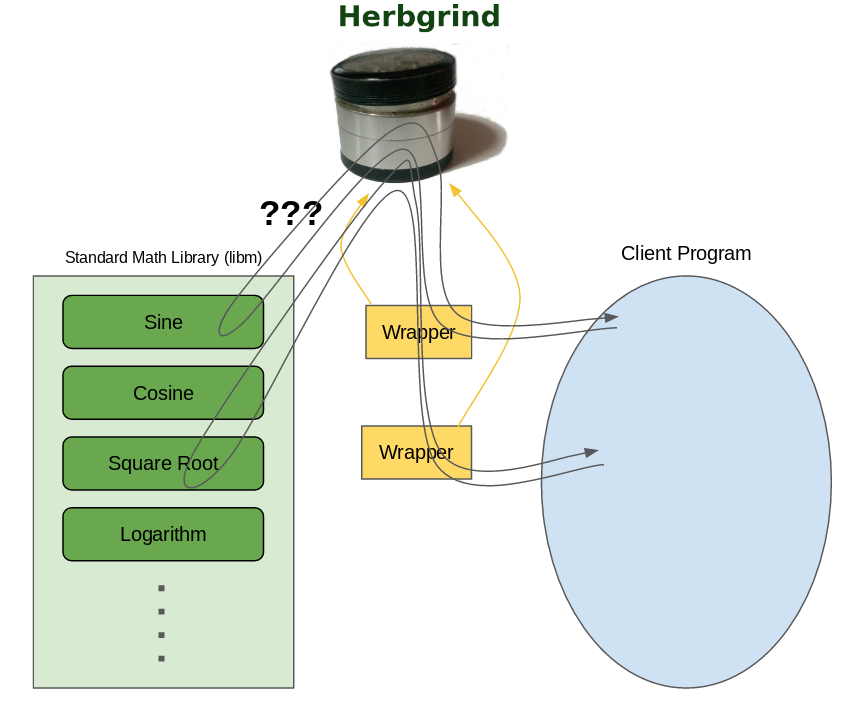
Since these functions are computed in libraries though, there isn’t a particular instruction we can look for to instrument them. Instead, we need to find the calls to these functions, and instrument the call as a whole. The normal instrumentation mechanism in Valgrind isn’t great for instrumenting function calls, because everything is broken down to basic pieces that don’t include control flow.
Luckily, Valgrind has another mechanism for working with function calls, called function wrapping. Function wrapping allows you to write your own replacement functions for any function, in the original binary or in a library. When the client program tries to call the wrapped function, it’ll get redirected to your function instead. From there you can replace the function entirely, or call the original underlying function with your own manipulation of the input and output. At least, in theory.
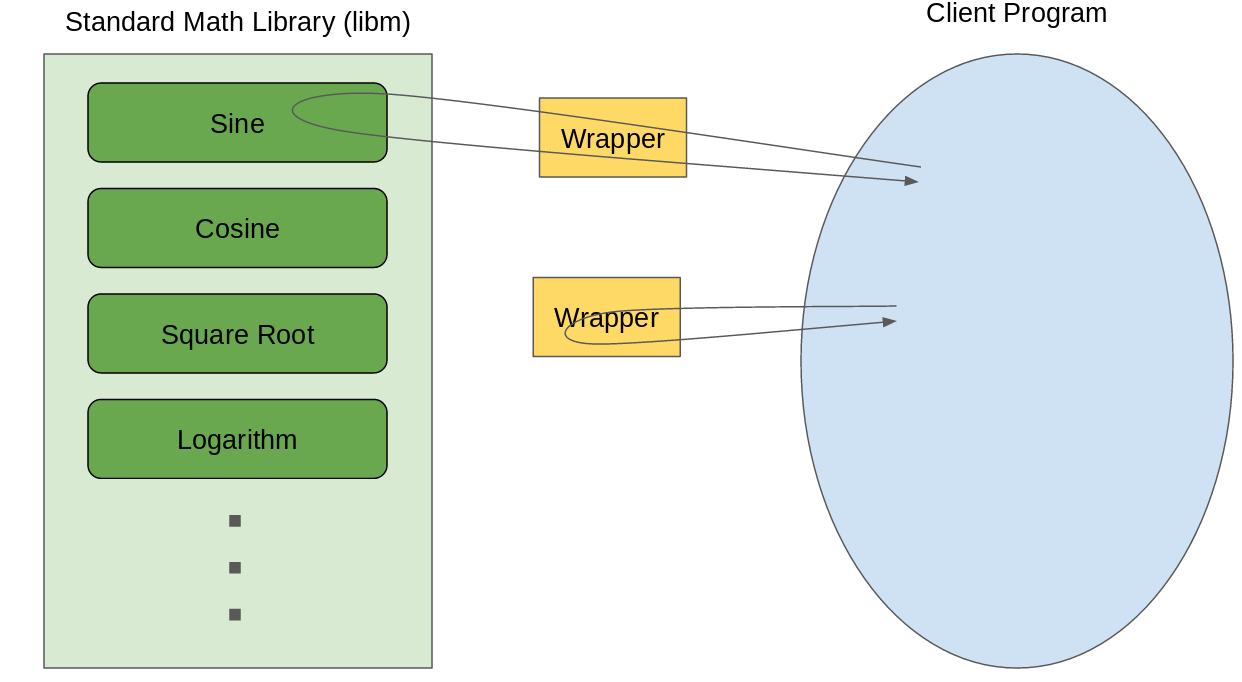
For our purposes, we’re going to wrap the calls to libm
implementations of math functions, but unfortunately we run into a
hitch when we try to call straight into the original
implementations. What we want to do is intercept the call to, say,
sqrt, and do the necessary bookkeeping to compute the exact
version. Then, call into the original version to get the computed
value, which we return to the client program.
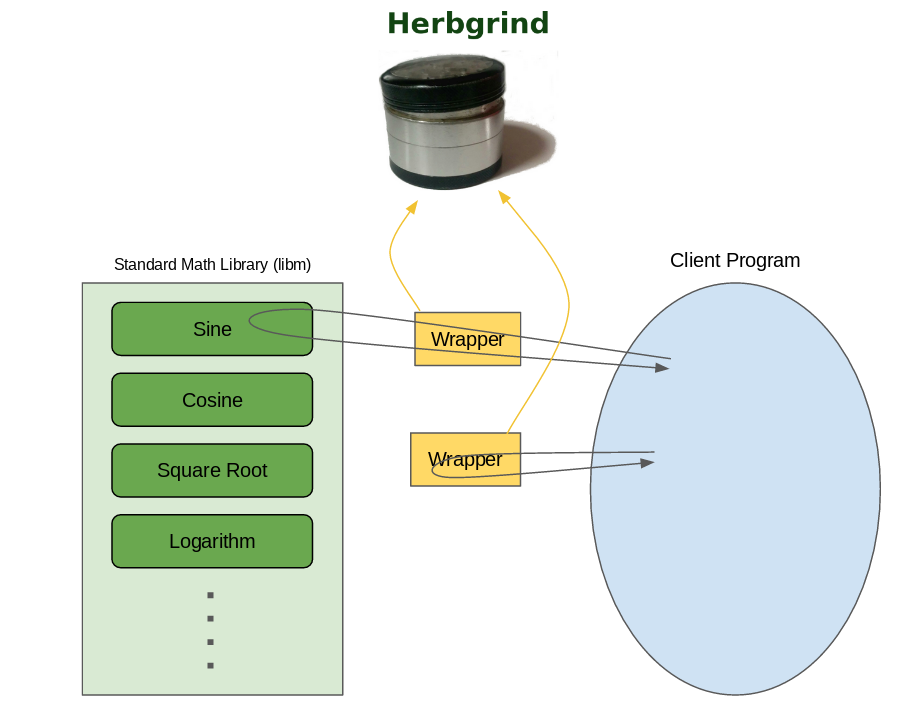
But Valgrind’s wrapping mechanism uses a very complex, low-level procedure to shuttle arguments back and forth between wrapped functions and their original implementation, and unfortunately it doesn’t currently support floating point arguments. So while the arguments make it into the wrapper fine, it’s not currently possible to pass floating point arguments down to the wrapped functions from there2.
So instead of calling into the original function directly, we’ll just
do everything inside tool code. In Herbgrind, when a call comes into a
wrapped math function its arguments get taken from the floating point
argument registers and put in memory. The wrapper allocates some
memory for the result too, and then passes pointers to the arguments
and result memory through to the tool code3, which can
compute the exact result, and simulate the low-precision result to
give back to the client program. Unfortunately, while tool code can
generally use regular function calls to access libraries, and
therefore doesn’t have a problem with passing floats to libm, it has
its own problems with accessing the standard math library. To
understand why, we’ll have to go down a bit of a rabbit hole.
Valgrind and the C Standard Library
We learned a little bit about the crazy things Valgrind does in this post. But what you may not know is that Valgrind is even crazier. You see, even though Valgrind has “host” and “client” code running at any given time, the two aren’t fully separated like they would be if it used a virtual machine, or some sort of process container. Instead, the Valgrind core, the tool logic (like that of Herbgrind), and the recompiled client code itself all runs together, in the same address space.
Woah.
Client programs expect to have all of memory to themselves, and it’s way to difficult to try to remap all of the memory accesses in the client program to a different set of memory. Luckily, in practice programs don’t tend to use ALL of the (virtual) memory space, just a few chunks in various places. Some of them are for the stack, others for the heap, and others for storing the program instructions. These locations don’t vary much across programs, and they almost always leave big regions of memory in between unmapped. That’s where Valgrind can slip itself in.

Valgrind, when it’s loading a client program, puts its own code at a special offset in memory where it’s unlikely to interfere with the client program4. It loads its libraries here, stores its data here, and generally operates independent from client memory.
Relocating the Valgrind code is easy, because it happens at compile time, before the compiler has committed to laying out memory. The only trouble is, not all the code that a Valgrind tool wants to execute is going to be available in source form and compiled alongside the tool; some of it is in libraries.
Libraries, like the C standard library, are separate pre-compiled objects that Valgrind code jumps into to perform certain functions. Most libraries you can get away with linking in statically, or not using at all, but the C standard library is a complex beast, and provides a lot of essential functionality.
The Valgrind solution? Re-implement it. From scratch.
The Valgrind implementation of the standard library has a few omissions, but it’s impressively complete. It’s certainly enough to do almost everything you could possibly want in your tool code5.
Back To Math Wrapping
The Valgrind standard library does have one major omission: it
doesn’t include libm the standard math library. If you try to link
in the normal libm to your tool code, you’ll quickly find that it
expects the C standard library to be in the normal place, and fails if
it’s not. So unfortunately, using the standard math library which the
client program has access to is out.
One solution is to use MPFR to simulate normal precision, but I find
that a little unsatisfying, since it’s not intended to be used that
way, and might not adhere accurately to what programs expect of a
normal libm implementation.
So instead, Herbgrind uses OpenLibm, an open
source cross-platform libm implementation. I was a little surprised
at how easy this was to make work: unlike the other dependencies like
GMP and MPFR, OpenLibm didn’t seem to rely on any libc specifics
that Valgrind didn’t provide, and it can link into Herbgrind with no
patching.
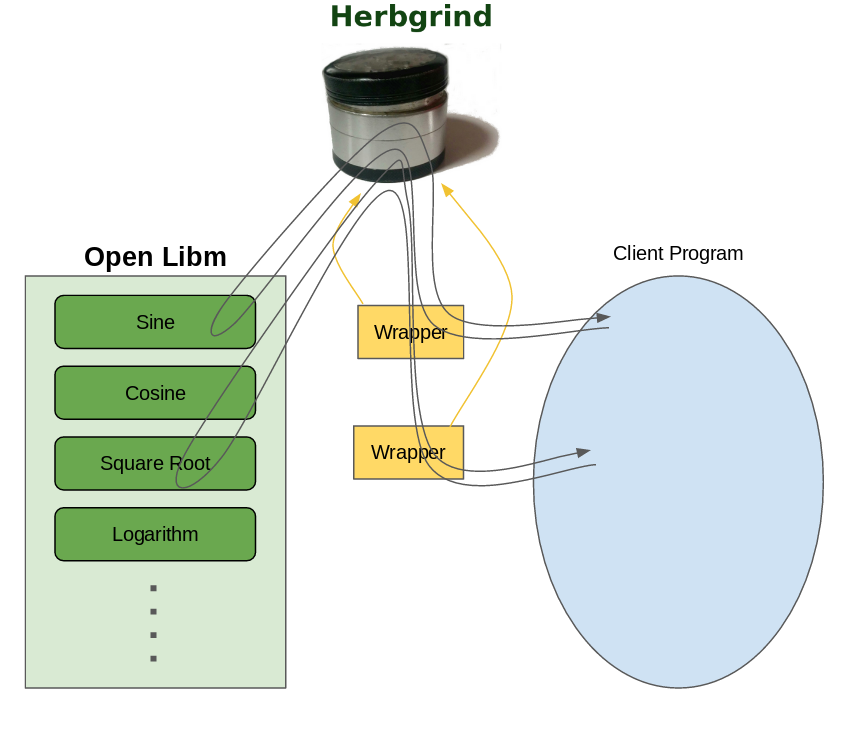
With all of that in place, we have no trouble providing high-precision
versions of both operations that are done in a single instructions,
and operations which are provided by the standard library. The
technique for wrapping library functions isn’t really specific to
libm either, so if you wanted to expand Herbgrind to run properly on
clients which use non-standard math libraries, all you’d need to do is
add a few lines of code to the wrapping file, and find some way to
compute those operations in high-precision.
-
Some processors actually do have a special “square root” instruction, but not all of them, and almost none have built in support for functions like “sine” or “logarithm”. ↩
-
I wondered for a long time whether I was just making some mistake when calling into the wrapped functions, but this mailing list response from Julian Seward, one of the authors of Valgrind, confirms that any argument passing outside of the standard integer calling convention is unsupported. ↩
-
Calling into tool code involves another piece of Valgrind hackery, called client calls. They have similar limiations to replacement function calls, which is why we only pass pointers, not floating point values directly. ↩
-
The offset used by default works for most programs, but you can change it at compile time if you want. ↩
-
While trying to do crazy input redirection stuff to repurpose some of the IR printing code, I found out there were a couple of missing system call interfaces related to manipulating pipes. I’m not sure if that’s a fundamental limitation, or if the authors just figured no one would need them. ↩